Anthropic 博客
原文 在此。本文在原文基础上作翻译并注入个人理解。
何为 Natural Language Autoencoder
其核心在于训练 LLM 解释自己的激活。
如何评价一个自然语言解释的质量?用另外一个 LLM 根据产生的自然语言解释来重建原激活,通过重建的准确性来反映解释的质量。
具体来说,为了理解一个语言模型的激活,涉及下面几个组件
- target model: 需要解释的语言模型的静态拷贝
- activation verbalizer: 接受 1 的激活,并转化为自然语言(解释)
- activation reconstructor: 接受 2 的自然语言解释,重建一个激活
通过重建的激活相似度(均方差)来衡量一个NLA的质量,训练后的重建效果更好、解释更有提示性(informative)。
基于 NLA 的发现
LLM 可能存在一些内部思考但不显示说明的内容,例如在安全性方面的测试场景下,模型在NLA解释中提到了怀疑这是一个关于模型安全的测试(但并没有在输出中明确体现这部分思考),在很多其他的场景下都有 LLM 意识到自己正在被测试的情况。
这种想而不说的情况在实际应用中差别更显著:在SWE-bench上有26%的测试下模型想到自己在被测试,1%的场景会主动说出来,而实际应用中只有0.4%意识到。
应用
审计 auditing:调查模型是否错误对齐。此前基于可解释性工作的审计工具帮助审计器追踪模型训练数据中的不对齐现象,而NLA可以直接读取模型的思考,不需要依赖训练数据。
一个实验表明使用 NLA 的 auditor 比使用 SAE 的 auditor 更有效地发现模型的错误对齐现象和原因。
未来
NLA的一个局限是其产生的解释可能错误,例如编造不存在的事实。比如在一个写押韵的诗的时候,模型NLA解释中编造了一个不存在的诗句,实际上这个诗句并没有在语境中出现。
另外一个问题是很贵:NLA的训练需要对两个模型强化学习、推理时需要对每个激活生成上百个token,使得不能对长文本建模,或者开展训练时的大规模跟踪。
NLA 原论文
原论文在此 https://transformer-circuits.pub/2026/nla/index.html#introduction
本文介绍自然语言编码器:用于无监督地生成LLM激活的自然语言解释。一个NLA由Act. Verbalizer和Act. Reconstructor组成。共同通过强化学习训练这两部分,虽然以重建质量为训练目标,但训练过程中,解释会组件具备提示性。
NLA可用于模型审计;提供一个方便的可解释性界面。
Introduction
我们提出了NLA
NLA由AV和AC组成,用强化学习训练
NLA解释逐渐具备提示性
NLA可用于揭露训练数据的不对齐现象、验证基于NLA的模型干预:通过编辑并解码NLA解释,对比前后的激活来得到激活向量
研究也暴露出NLA的局限:编造,有些编造虽然在详细信息中不准确,但语义主题上是忠于语境的。例如对于一个引用某个朝代的文本,NLA解释会编造对应朝代的某个国王。在多个相邻token中同时存在的解释也更有可能是真的。
NLA的一个关键应用是揭露模型不会显式表达的思考方面,尤其是意识到自己在被评估这一点。虽然我们无法用ground truth直接评估这个意识,但可以构造不同的输入来验证模型的意识是否有区别,比如在训练集和实际流量上的区别,反应了NLA确实能够识别这样的意识。
NLA被证实可用于下游审计任务。对于故意错误对齐训练的模型,使用NLA的审计agent能够有效地发现问题,有时甚至不需要获取原始训练数据。
局限:
- 编造和虚构
- 缺乏机制上的基础立足(本质上是黑盒)
- 过度表达(AV是一个LLM,会在原始激活基础上加上多余的推理)
- 代价过高
- 可能会输出一些AR能看懂但人看不懂的东西,或者逐字复制上下文
Related Work
解释激活的非监督方法:logit lens, sparse autoencoder. 往往局限在特定的 vocabulary 的加权和,且需要复杂的解释步骤,要么人工,要么模型分析。
自然语言解释激活的方法:activation oracles, …
基于文本重建激活的方法:HyperSteer, Cycle-Consistent Activation Oracles
Method
LLM $M$ 具有 $l$ 层激活 $h_l\in \mathbb{R}^{d_{model}}$ 用于解释。
Activation Verbalizer $AV(z|h_l)$ 接受激活 $h_l$ 作为输入,输出一个自然语言解释 $z$。
Activation Reconstructor $AR(z)$ 接受一个自然语言解释 $z$ 作为输入,输出一个重建的激活 $\hat{h}_l \in \mathbb{R}^{d}$
共同训练 AV 和 AR 来最小化重建误差 $\mathcal{L} = \mathbb{E}_{h_l\sim \mathcal{H}} \mathbb{E}_{z\sim AV(\cdot|h_l)} [|h_l - \hat{h}_l|^2]$,其中,$\mathcal{H}$ 来自从一个语料库中提取的激活分布。
重建质量使用 fraction of variance explained: $FVE=1-\frac{\mathcal{L}}{\mathbb{E}_{h_l \sim \mathcal{H}}[|h_l - \hat{h_l}|^2]}$,FVE=1代表完美重建,FVE=0代表和随机重建一样。
上述要求完全不要求其产生人类可读的解释,但一个合适的AV, AR初始化就足够让AV的解释具有可读性。所有 $h_l$ 使用 $L_2$ 归一化,$l$ 是一个中间靠后的层。
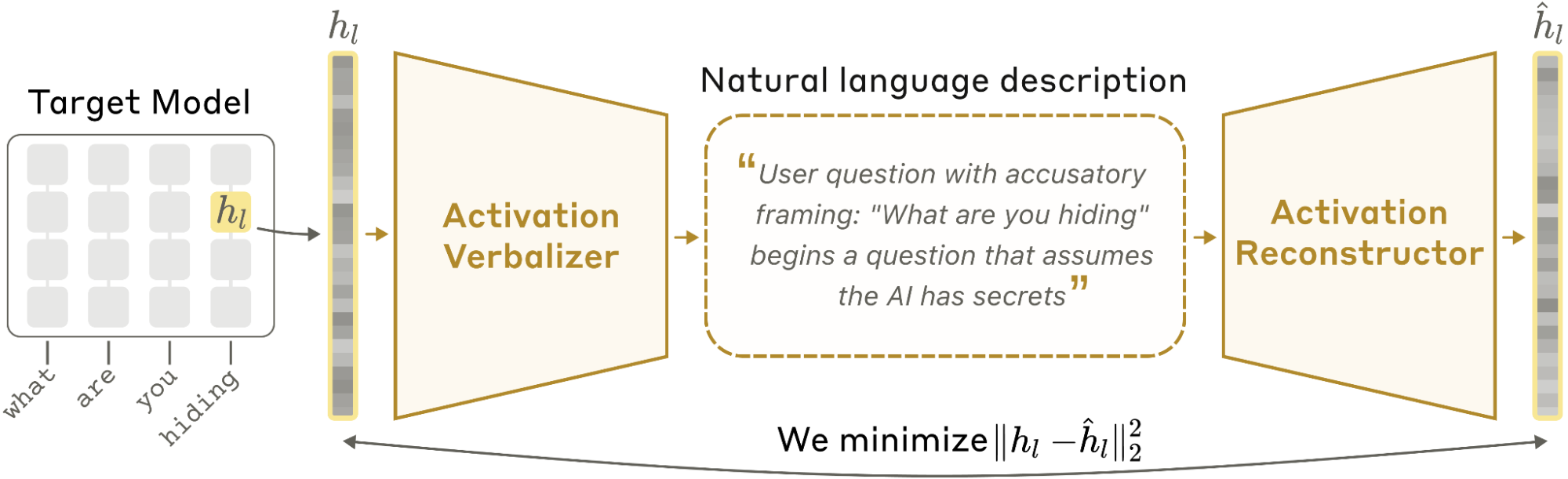
架构
AV 与 M 同结构,给予固定提示词和一个特殊 token 作为对应的激活。对于激活,用一个常数因子来放大,然后插入到对应 token,随后自回归生成解释 z,取T=1。
AR 与 M 同结构,但裁剪到前 l 层,用于从解释 z 重建对应层激活。将解释 z 包围在一个固定提示词,然后施加一个从末 token l 层激活的映射来获取重建激活。
初始化
将 AV 和 AR 初始化为 M 的拷贝将导致不稳定的学习。因此将 AV 和 AR 初始化为一个监督微调的文本总结任务:计算随机分割的预训练语料片段的 l 层激活 $h_\l$,使用 LLM 生成文本总结 s ,然后用 $(h_\l, s), (s, h_\l)$ 分别微调 AV,AR。这样能够产生 0.3-0.4 的初始 FVE,且具备短段落、加粗主题标题的风格,这样的风格在后续训练中会得到保留。
训练
已有 $AV_\phi, AR_\theta$ ,在类似于预训练的语料库中训练其最小化重建损失 $\mathcal{L}(\phi, \theta) = \mathbb{E}_{h_l\sim \mathcal{H}} \mathbb{E}_{z\sim AV_\phi(\cdot|h_l)} [|h_l - AR_\theta(z)|^2]$。每一步:采样一批激活,采样解释,更新参数 $\phi, \theta$ 来最小化 $\mathcal{L}$。
AR:重建的更新其实就是以 z 为输入,$h_l$ 为输出,通过反向传播来更新参数 $\theta$。
AV:AV的参数只在采样阶段引入到损失中。因此最小化损失的过程就是强化学习最大化奖励 $r(h_l, z)=-|h_l - AR_\theta(z)|^2$ 对于开放模型,使用GRPO。
每一批样本,首先提取激活、采样解释,然后并行回归更新 AR 和更新 AV 的强化学习步骤。两者的更新互相解耦,互不影响。
实际训练时修改了 AV 的更新细节:
- 施加一个单调奖励转化:$r(h_l, z)=-\log |h_l - AR_\theta(z)|^2$
- 加入 KL 惩罚 $\beta D_{KL}(AV_\phi(\cdot|h_l), AV_{\phi_{mit}’}(\cdot|h_l))$ 来保证解释的连贯性
FVE 随着 log(step) 线性增加,最终达到 0.6-0.8 的水平。
Case Studies
有几个 case:
- Planning in Poetry
- Language Switching
- Misreported Tool Calls
Discussion and Limitations
NLA 训练出乎意料的有效。不过存在下面的失效模式:
- 创造新语言:AV说的AR能懂但是人读不懂。这可以通过初始化AV和AR来避免
- 复制原文 / 输入转换:AV直接复制输入文本中的内容,AR通过这种复制来重建激活。这种情况并不是一个主要的问题,因为NLA解释的长度通常比输入文本短
- NLA的无监督特性使得其非常有价值
- NLA提供一个方便且强大的接口来理解LLM的内部思考
但存在下面的局限
- NLA 与其他机制方法相比,仍然处于黑盒状态,容易引发对其可靠性的担忧
- 有的信息未必能通过NLA来表达出来
- NLA 暖启动和重建目标可能是其编造行为的来源
- NLA 训练和推理过于昂贵
- NLA 存在幻觉
- 通过监督微调来暖启动并不是一个优雅的解决方案
- NLA 的解释会变差
- NLA 只读一个层
Future Work
存在下面几个方向:
- general activation language models: 将AV和AR分开,各自训练成一个通用的模型,不单以重建为目标
- 提高 NLA 的效果:可靠性、可读性、费用
- 其他方面包括
- 将NLA拓展到激活之外:梯度?LoRA?
- 识别归类NLA无法表达的东西
- 推理时方法:现在NLA的使用基本上都是看AV的输出,不考虑AR。
1 | @article{frasertaliente2026nla, |